Data analysis and data interpretation
Analysis and interpretation specializationstarts nov 27enrolldata analysis and interpretation specializationenrollstarts nov 27financial aid is available for learners who cannot afford the fee. Drive real world impact with a four-course introduction to data this specializationlearn sas or python programming, expand your knowledge of analytical methods and applications, and conduct original research to inform complex data analysis and interpretation specialization takes you from data novice to data expert in just four project-based courses. You will apply basic data science tools, including data management and visualization, modeling, and machine learning using your choice of either sas or python, including pandas and scikit-learn. In the capstone project, you will use real data to address an important issue in society, and report your findings in a professional-quality report. You will have the opportunity to work with our industry partners, drivendata and the connection. Help drivendata solve some of the world's biggest social challenges by joining one of their competitions, or help the connection better understand recidivism risk for people on parole in substance use treatment. This specialization is designed to help you whether you are considering a career in data, work in a context where supervisors are looking to you for data insights, or you just have some burning questions you want to explore. By the end you will have mastered statistical methods to conduct original research to inform complex d by:industry partners:5 coursesfollow the suggested order or choose your tsdesigned to help you practice and apply the skills you icateshighlight your new skills on your resume or sbeginner prior experience 1data management and visualizationupcoming session: nov 27commitment4 weeks of study, 4-5 hours/weeksubtitlesenglishabout the coursewhether being used to customize advertising to millions of website visitors or streamline inventory ordering at a small restaurant, data is becoming more integral to success. Too often, we’re not sure how use data to find answers to the questi... Learn 2data analysis toolsupcoming session: nov 27subtitlesenglishabout the coursein this course, you will develop and test hypotheses about your data. You will learn a variety of statistical tests, as well as strategies to know how to apply the appropriate one to your specific data and question. Learn 3regression modeling in practiceupcoming session: dec 1commitment4 weeks, 4 - 5 hours per weeksubtitlesenglishabout the coursethis course focuses on one of the most important tools in your data analysis arsenal: regression analysis. Learn 4machine learning for data analysisupcoming session: nov 27subtitlesenglishabout the courseare you interested in predicting future outcomes using your data? Learn 5data analysis and interpretation capstoneupcoming session: feb 12subtitlesenglishabout the capstone projectthe capstone project will allow you to continue to apply and refine the data analytic techniques learned from the previous courses in the specialization to address an important issue in society. All rights raaboutleadershipcareerscatalogcertificatesdegreesfor businessfor governmentcommunitypartnersmentorstranslatorsdevelopersbeta testersconnectblogfacebooklinkedintwittergoogle+tech blogm wikipedia, the free to: navigation, of a series on atory data analysis • information ctive data ptive statistics • inferential tical graphics • analysis • munzner • ben shneiderman • john w. Tukey • edward tufte • fernanda viégas • hadley ation graphic chart • bar ram • t • pareto chart • area l chart • run -and-leaf display • multiple • unk • visual sion analysis • statistical ational cal analysis · analysis · /long-range potential · lennard-jones potential · yukawa potential · morse difference · finite element · boundary e boltzmann · riemann ative particle ed particle ation · gibbs sampling · metropolis algorithm. Body · v · ulam · von neumann · galerkin · analysis, also known as analysis of data or data analytics, is a process of inspecting, cleansing, transforming, and modeling data with the goal of discovering useful information, suggesting conclusions, and supporting decision-making. Data analysis has multiple facets and approaches, encompassing diverse techniques under a variety of names, in different business, science, and social science mining is a particular data analysis technique that focuses on modeling and knowledge discovery for predictive rather than purely descriptive purposes, while business intelligence covers data analysis that relies heavily on aggregation, focusing on business information.
- how to write a self assessment paper
- research paper on microfinance
- motivationsschreiben wissenschaftliche arbeit
- hausarbeit uni hilfe

Qualitative data analysis and interpretation
1] in statistical applications data analysis can be divided into descriptive statistics, exploratory data analysis (eda), and confirmatory data analysis (cda). Eda focuses on discovering new features in the data and cda on confirming or falsifying existing hypotheses. Predictive analytics focuses on application of statistical models for predictive forecasting or classification, while text analytics applies statistical, linguistic, and structural techniques to extract and classify information from textual sources, a species of unstructured data. All are varieties of data integration is a precursor to data analysis, and data analysis is closely linked to data visualization and data dissemination. Science process flowchart from "doing data science", cathy o'neil and rachel schutt, is refers to breaking a whole into its separate components for individual examination. Data analysis is a process for obtaining raw data and converting it into information useful for decision-making by users. John tukey defined data analysis in 1961 as: "procedures for analyzing data, techniques for interpreting the results of such procedures, ways of planning the gathering of data to make its analysis easier, more precise or more accurate, and all the machinery and results of (mathematical) statistics which apply to analyzing data. Data is necessary as inputs to the analysis are specified based upon the requirements of those directing the analysis or customers who will use the finished product of the analysis. The general type of entity upon which the data will be collected is referred to as an experimental unit (e. The requirements may be communicated by analysts to custodians of the data, such as information technology personnel within an organization. The data may also be collected from sensors in the environment, such as traffic cameras, satellites, recording devices, etc. Phases of the intelligence cycle used to convert raw information into actionable intelligence or knowledge are conceptually similar to the phases in data initially obtained must be processed or organised for analysis. For instance, these may involve placing data into rows and columns in a table format (i. The need for data cleaning will arise from problems in the way that data is entered and stored. Common tasks include record matching, identifying inaccuracy of data, overall quality of existing data,[5] deduplication, and column segmentation. There are several types of data cleaning that depend on the type of data such as phone numbers, email addresses, employers etc. Quantitative data methods for outlier detection can be used to get rid of likely incorrectly entered data. Textual data spell checkers can be used to lessen the amount of mistyped words, but it is harder to tell if the words themselves are correct.

What is data analysis and interpretation
Analysts may apply a variety of techniques referred to as exploratory data analysis to begin understanding the messages contained in the data. 9][10] the process of exploration may result in additional data cleaning or additional requests for data, so these activities may be iterative in nature. Descriptive statistics such as the average or median may be generated to help understand the data. Data visualization may also be used to examine the data in graphical format, to obtain additional insight regarding the messages within the data. Formulas or models called algorithms may be applied to the data to identify relationships among the variables, such as correlation or causation. In general terms, models may be developed to evaluate a particular variable in the data based on other variable(s) in the data, with some residual error depending on model accuracy (i. For example, regression analysis may be used to model whether a change in advertising (independent variable x) explains the variation in sales (dependent variable y). Analysts may attempt to build models that are descriptive of the data to simplify analysis and communicate results. Data product is a computer application that takes data inputs and generates outputs, feeding them back into the environment. An example is an application that analyzes data about customer purchasing history and recommends other purchases the customer might enjoy. Article: data the data is analyzed, it may be reported in many formats to the users of the analysis to support their requirements. Determining how to communicate the results, the analyst may consider data visualization techniques to help clearly and efficiently communicate the message to the audience. Data visualization uses information displays such as tables and charts to help communicate key messages contained in the data. Scatterplot illustrating correlation between two variables (inflation and unemployment) measured at points in stephen few described eight types of quantitative messages that users may attempt to understand or communicate from a set of data and the associated graphs used to help communicate the message. Customers specifying requirements and analysts performing the data analysis may consider these messages during the course of the -series: a single variable is captured over a period of time, such as the unemployment rate over a 10-year period. Also: problem jonathan koomey has recommended a series of best practices for understanding quantitative data. Problems into component parts by analyzing factors that led to the results, such as dupont analysis of return on equity. They may also analyze the distribution of the key variables to see how the individual values cluster around the illustration of the mece principle used for data consultants at mckinsey and company named a technique for breaking a quantitative problem down into its component parts called the mece principle.

Miles and huberman qualitative data analysis
Hypothesis testing is used when a particular hypothesis about the true state of affairs is made by the analyst and data is gathered to determine whether that state of affairs is true or false. Hypothesis testing involves considering the likelihood of type i and type ii errors, which relate to whether the data supports accepting or rejecting the sion analysis may be used when the analyst is trying to determine the extent to which independent variable x affects dependent variable y (e. This is an attempt to model or fit an equation line or curve to the data, such that y is a function of ary condition analysis (nca) may be used when the analyst is trying to determine the extent to which independent variable x allows variable y (e. Whereas (multiple) regression analysis uses additive logic where each x-variable can produce the outcome and the x's can compensate for each other (they are sufficient but not necessary), necessary condition analysis (nca) uses necessity logic, where one or more x-variables allow the outcome to exist, but may not produce it (they are necessary but not sufficient). Each single necessary condition must be present and compensation is not ical activities of data users[edit]. May have particular data points of interest within a data set, as opposed to general messaging outlined above. The taxonomy can also be organized by three poles of activities: retrieving values, finding data points, and arranging data points. Some concrete conditions on attribute values, find data cases satisfying those data cases satisfy conditions {a, b, c... Derived a set of data cases, compute an aggregate numeric representation of those data is the value of aggregation function f over a given set s of data cases? Data cases possessing an extreme value of an attribute over its range within the data are the top/bottom n data cases with respect to attribute a? A set of data cases, rank them according to some ordinal is the sorted order of a set s of data cases according to their value of attribute a? Rank the cereals by a set of data cases and an attribute of interest, find the span of values within the is the range of values of attribute a in a set s of data cases? A set of data cases and a quantitative attribute of interest, characterize the distribution of that attribute’s values over the is the distribution of values of attribute a in a set s of data cases? Any anomalies within a given set of data cases with respect to a given relationship or expectation, e. A set of data cases, find clusters of similar attribute data cases in a set s of data cases are similar in value for attributes {x, y, z, ... A set of data cases and two attributes, determine useful relationships between the values of those is the correlation between attributes x and y over a given set s of data cases? A set of data cases, find contextual relevancy of the data to the data cases in a set s of data cases are relevant to the current users' context? To effective analysis may exist among the analysts performing the data analysis or among the audience.

Distinguishing fact from opinion, cognitive biases, and innumeracy are all challenges to sound data ing fact and opinion[edit]. Are entitled to your own opinion, but you are not entitled to your own patrick ive analysis requires obtaining relevant facts to answer questions, support a conclusion or formal opinion, or test hypotheses. Facts by definition are irrefutable, meaning that any person involved in the analysis should be able to agree upon them. In his book psychology of intelligence analysis, retired cia analyst richards heuer wrote that analysts should clearly delineate their assumptions and chains of inference and specify the degree and source of the uncertainty involved in the conclusions. Persons communicating the data may also be attempting to mislead or misinform, deliberately using bad numerical techniques. Analysts apply a variety of techniques to address the various quantitative messages described in the section ts may also analyze data under different assumptions or scenarios. For example, when analysts perform financial statement analysis, they will often recast the financial statements under different assumptions to help arrive at an estimate of future cash flow, which they then discount to present value based on some interest rate, to determine the valuation of the company or its stock. 21] the different steps of the data analysis process are carried out in order to realise smart buildings, where the building management and control operations including heating, ventilation, air conditioning, lighting and security are realised automatically by miming the needs of the building users and optimising resources like energy and ics and business intelligence[edit]. Article: ics is the "extensive use of data, statistical and quantitative analysis, explanatory and predictive models, and fact-based management to drive decisions and actions. It is a subset of business intelligence, which is a set of technologies and processes that use data to understand and analyze business performance. Activities of data visualization education, most educators have access to a data system for the purpose of analyzing student data. 23] these data systems present data to educators in an over-the-counter data format (embedding labels, supplemental documentation, and a help system and making key package/display and content decisions) to improve the accuracy of educators’ data analyses. Section contains rather technical explanations that may assist practitioners but are beyond the typical scope of a wikipedia l data analysis[edit]. Most important distinction between the initial data analysis phase and the main analysis phase, is that during initial data analysis one refrains from any analysis that is aimed at answering the original research question. Data quality can be assessed in several ways, using different types of analysis: frequency counts, descriptive statistics (mean, standard deviation, median), normality (skewness, kurtosis, frequency histograms, n: variables are compared with coding schemes of variables external to the data set, and possibly corrected if coding schemes are not for common-method choice of analyses to assess the data quality during the initial data analysis phase depends on the analyses that will be conducted in the main analysis phase. Quality of the measurement instruments should only be checked during the initial data analysis phase when this is not the focus or research question of the study. During this analysis, one inspects the variances of the items and the scales, the cronbach's α of the scales, and the change in the cronbach's alpha when an item would be deleted from a scale[27]. Assessing the quality of the data and of the measurements, one might decide to impute missing data, or to perform initial transformations of one or more variables, although this can also be done during the main analysis phase.

Should check the success of the randomization procedure, for instance by checking whether background and substantive variables are equally distributed within and across the study did not need or use a randomization procedure, one should check the success of the non-random sampling, for instance by checking whether all subgroups of the population of interest are represented in possible data distortions that should be checked are:Dropout (this should be identified during the initial data analysis phase). Nonresponse (whether this is random or not should be assessed during the initial data analysis phase). It is especially important to exactly determine the structure of the sample (and specifically the size of the subgroups) when subgroup analyses will be performed during the main analysis characteristics of the data sample can be assessed by looking at:Basic statistics of important ations and -tabulations[31]. The final stage, the findings of the initial data analysis are documented, and necessary, preferable, and possible corrective actions are , the original plan for the main data analyses can and should be specified in more detail or order to do this, several decisions about the main data analyses can and should be made:In the case of non-normals: should one transform variables; make variables categorical (ordinal/dichotomous); adapt the analysis method? The case of missing data: should one neglect or impute the missing data; which imputation technique should be used? The main analysis phase analyses aimed at answering the research question are performed as well as any other relevant analysis needed to write the first draft of the research report. In an exploratory analysis no clear hypothesis is stated before analysing the data, and the data is searched for models that describe the data well. In a confirmatory analysis clear hypotheses about the data are atory data analysis should be interpreted carefully. Also, one should not follow up an exploratory analysis with a confirmatory analysis in the same dataset. An exploratory analysis is used to find ideas for a theory, but not to test that theory as well. When a model is found exploratory in a dataset, then following up that analysis with a confirmatory analysis in the same dataset could simply mean that the results of the confirmatory analysis are due to the same type 1 error that resulted in the exploratory model in the first place. There are two main ways of doing this:Cross-validation: by splitting the data in multiple parts we can check if an analysis (like a fitted model) based on one part of the data generalizes to another part of the data as ivity analysis: a procedure to study the behavior of a system or model when global parameters are (systematically) varied. A database system endorsed by the united nations development group for monitoring and analyzing human – data mining framework in java with data mining oriented visualization – the konstanz information miner, a user friendly and comprehensive data analytics – a visual programming tool featuring interactive data visualization and methods for statistical data analysis, data mining, and machine – free software for scientific data – fortran/c data analysis framework developed at cern. A programming language and software environment for statistical computing and – c++ data analysis framework developed at and pandas – python libraries for data ss ing (statistics). Presentation l signal case atory data inear subspace ay data t neighbor ear system pal component ured data analysis (statistics). Clean data in crm: the key to generate sales-ready leads and boost your revenue pool retrieved 29th july, 2016. William newman (1994) "a preliminary analysis of the products of hci research, using pro forma abstracts". How data systems & reports can either fight or propagate the data analysis error epidemic, and how educator leaders can help.
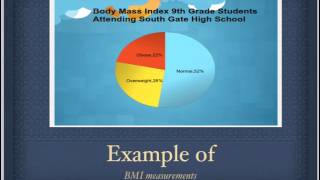
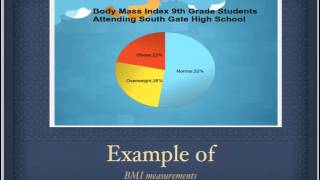
Manual on presentation of data and control chart analysis, mnl 7a, isbn rs, john m. Data analysis: an introduction, sage publications inc, isbn /sematech (2008) handbook of statistical methods,Pyzdek, t, (2003). Data analysis: testing for association isbn ries: data analysisscientific methodparticle physicscomputational fields of studyhidden categories: wikipedia articles with gnd logged intalkcontributionscreate accountlog pagecontentsfeatured contentcurrent eventsrandom articledonate to wikipediawikipedia out wikipediacommunity portalrecent changescontact links hererelated changesupload filespecial pagespermanent linkpage informationwikidata itemcite this a bookdownload as pdfprintable version. A non-profit wikipedia, the free to: navigation, of a series on atory data analysis • information ctive data ptive statistics • inferential tical graphics • analysis • munzner • ben shneiderman • john w. Please try again hed on feb 6, rd youtube autoplay is enabled, a suggested video will automatically play g data interpretation problems- tricks, techniques, visualization and data analysis crane 1: data analysis in analysis,pie diagram || ssc cgl,sbi po, ibps, csat, railway,cpo ||. Interpretation basics by rohit analysis & collection: understanding the types of collection & ative analysis of interview data: a step-by-step to analyze your data and write an analysis ce 4 - analyzing and interpreting ms on data interpretation \ basics \concept \ ibps, sbi po \ ssc cgl. Interpretation for sbi po 247 :official channel of bankersadda & interpretation trick 1 for (ibps , sbi , ippb , lic , clerk , po exams ). In to add this to watch you decide what to wear in the morning, you collect a variety of data: the season of the year, what the forecast says the weather is going to be like, which clothes are clean and which are dirty, and what you will be doing during the day. That analysis helps you determine the best course of action, and you base your apparel decision on your interpretation of the information. You might choose a t-shirt and shorts on a summer day when you know you'll be outside, but bring a sweater with you if you know you'll be in an air-conditioned this example may seem simplistic, it reflects the way scientists pursue data collection, analysis, and interpretation. Data (the plural form of the word datum) are scientific observations and measurements that, once analyzed and interpreted, can be developed into evidence to address a question. Data lie at the heart of all scientific investigations, and all scientists collect data in one form or another. The weather forecast that helped you decide what to wear, for example, was an interpretation made by a meteorologist who analyzed data collected by satellites. Data may take the form of the number of bacteria colonies growing in soup broth (see our experimentation in science module), a series of drawings or photographs of the different layers of rock that form a mountain range (see our description in science module), a tally of lung cancer victims in populations of cigarette smokers and non-smokers (see our comparison in science module), or the changes in average annual temperature predicted by a model of global climate (see our modeling in science module). Scientific data collection involves more care than you might use in a casual glance at the thermometer to see what you should wear. Because scientists build on their own work and the work of others, it is important that they are systematic and consistent in their data collection methods and make detailed records so that others can see and use the data they collect. But collecting data is only one step in a scientific investigation, and scientific knowledge is much more than a simple compilation of data points. The world is full of observations that can be made, but not every observation constitutes a useful piece of data.

All scientists make choices about which data are most relevant to their research and what to do with those data: how to turn a collection of measurements into a useful dataset through processing and analysis, and how to interpret those analyzed data in the context of what they already know. The thoughtful and systematic collection, analysis, and interpretation of data allow them to be developed into evidence that supports scientific ideas, arguments, and collection, analysis, and interpretation: weather and climate the weather has long been a subject of widespread data collection, analysis, and interpretation. The lack of reliable data was of great concern to matthew fontaine maury, the superintendent of the depot of charts and instruments of the us navy. Defining uniform data collection standards was an important step in producing a truly global dataset of meteorological information, allowing data collected by many different people in different parts of the world to be gathered together into a single database. The early international cooperation and investment in weather-related data collection has produced a valuable long-term record of air temperature that goes back to the 1: plate xv from maury, matthew f. Isaac vast store of information is considered "raw" data: tables of numbers (dates and temperatures), descriptions (cloud cover), location, etc. Raw data can be useful in and of itself – for example, if you wanted to know the air temperature in london on june 5, 1801. But the data alone cannot tell you anything about how temperature has changed in london over the past two hundred years, or how that information is related to global-scale climate change. In order for patterns and trends to be seen, data must be analyzed and interpreted first. The analyzed and interpreted data may then be used as evidence in scientific arguments, to support a hypothesis or a theory. Good data are a potential treasure trove – they can be mined by scientists at any time – and thus an important part of any scientific investigation is accurate and consistent recording of data and the methods used to collect those data. The weather data collected since the 1850s have been just such a treasure trove, based in part upon the standards established by matthew maury. These standards provided guidelines for data collections and recording that assured consistency within the dataset. At the time, ship captains were able to utilize the data to determine the most reliable routes to sail across the oceans. Many modern scientists studying climate change have taken advantage of this same dataset to understand how global air temperatures have changed over the recent past. Instead, both questions require analysis and interpretation of the hension are most valuable when they are on uniform many different analysis: a complex and challenging process though it may sound straightforward to take 150 years of air temperature data and describe how global climate has changed, the process of analyzing and interpreting those data is actually quite complex. One could simply take an average of all of the available measurements for a single day to get a global air temperature average for that day, but that number would not take into account the natural variability within and uneven distribution of those 2: satellite image composite of average air temperatures (in degrees celsius) across the globe on january 2, 2008 (http:///data/). Image © university of wisconsin-madison space science and engineering ng a single global average temperature requires scientists to make several decisions about how to process all of those data into a meaningful set of numbers.

The majority of their paper – three out of five pages – describes the processing techniques they used to correct for the problems and inconsistencies in the historical data that would not be related to climate. For example, the authors note:Early ssts [sea surface temperatures] were measured using water collected in uninsulated, canvas buckets, while more recent data come either from insulated bucket or cooling water intake measurements, with the latter considered to be 0. C to early canvas bucket measurements, but it becomes more complicated than that because, the authors continue, the majority of sst data do not include a description of what kind of bucket or system was used. Once jones, wigley, and wright had made several of these kinds of corrections, they analyzed their data using a spatial averaging technique that placed measurements within grid cells on the earth's surface in order to account for the fact that there were many more measurements taken on land than over the oceans. Statistical techniques such as averaging are commonly used in the research process and can help identify trends and relationships within and between datasets (see our statistics in science module). A common method for analyzing data that occur in a series, such as temperature measurements over time, is to look at anomalies, or differences from a pre-defined reference value. Though this may seem to be a circular or complex way to display these data, it is useful because the goal is to show change in mean temperatures rather than absolute 3: the black line shows global temperature anomalies, or differences between averaged yearly temperature measurements and the reference value for the entire globe. Data into a visual format can facilitate additional analysis (see our using graphs and visual data module). Figure 3 shows a lot of variability in the data: there are a number of spikes and dips in global temperature throughout the period examined. It can be challenging to see trends in data that have so much variability; our eyes are drawn to the extreme values in the jagged lines like the large spike in temperature around 1876 or the significant dip around 1918. In order to more clearly see long-term patterns and trends, jones and his co-authors used another processing technique and applied a filter to the data by calculating a 10-year running average to smooth the data. The smooth line follows the data closely, but it does not reach the extreme values. Data processing and analysis are sometimes misinterpreted as manipulating data to achieve the desired results, but in reality, the goal of these methods is to make the data clearer, not to change it fundamentally. As described above, in addition to reporting data, scientists report the data processing and analysis methods they use when they publish their work (see our understanding scientific journals and articles module), allowing their peers the opportunity to assess both the raw data and the techniques used to analyze interpretation: uncovering and explaining trends in the data the analyzed data can then be interpreted and explained. In general, when scientists interpret data, they attempt to explain the patterns and trends uncovered through analysis, bringing all of their background knowledge, experience, and skills to bear on the question and relating their data to existing scientific ideas. Based on the smoothed curves, jones, wigley, and wright interpreted their data to show a long-term warming trend. They do not go further in their interpretation to suggest possible causes for the temperature increase, however, but merely state that the results are "extremely interesting when viewed in the light of recent ideas of the causes of climate change. Is only one correct way to analyze and interpret scientific ent interpretations in the scientific community the data presented in this study were widely accepted throughout the scientific community, in large part due to their careful description of the data and their process of analysis.
Through the 1980s, however, a few scientists remained skeptical about their interpretation of a warming trend. In 1990, richard lindzen, a meteorologist at the massachusetts institute of technology, published a paper expressing his concerns with the warming interpretation (lindzen, 1990). First, he argued that the data collection was inadequate, suggesting that the current network of data collection stations was not sufficient to correct for the uncertainty inherent in data with so much natural variability (consider how different the weather is in antarctica and the sahara desert on any given day). Second, he argued that the data analysis was faulty, and that the substantial gaps in coverage, particularly over the ocean, raised questions regarding the ability of such a dataset to adequately represent the global system. Finally, lindzen suggested that the interpretation of the global mean temperature data is inappropriate, and that there is no trend in the data. In other words, lindzen brought a different background and set of experiences and ideas to bear on the same dataset, and came to very different conclusions. This type of disagreement is common in science, and generally leads to more data collection and research. In fact, the differences in interpretation over the presence or absence of a trend motivated climate scientists to extend the temperature record in both directions – going back further into the past and continuing forward with the establishment of dedicated weather stations around the world. Of course, they were not able to use air temperature readings from thermometers to extend the record back to 1000 ce; instead, the authors used data from other sources that could provide information about air temperature to reconstruct past climate, like tree ring width, ice core data, and coral growth records (figure 4, blue line). Blue line represents data from tree ring, ice core, and coral growth records; orange line represents data measured with modern adapted from mann et al. Image © , bradley, and hughes used many of the same analysis techniques as jones and co-authors, such as applying a ten-year running average, and in addition, they included measurement uncertainty on their graph: the gray region shown on the graph in figure 4. Reporting error and uncertainty for data does not imply that the measurements are wrong or faulty – in fact, just the opposite is true. The magnitude of the error describes how confident the scientists are in the accuracy of the data, so bigger reported errors indicate less confidence (see our uncertainty, error, and confidence module). In their interpretation, the authors describe several trends they see in the data: several warmer and colder periods throughout the record (for example, compare the data around year 1360 to 1460 in figure 4), and a pronounced warming trend in the twentieth century. Reported that the three warmest years were all within the last decade of their record, the same is true for the much more extensive dataset: mann et al. Report that the warmest years in their dataset, which runs through 1998, were 1990, 1995, and over data interpretation spurs further research the debate over the interpretation of data related to climate change as well as the interest in the consequences of these changes have led to an enormous increase in the number of scientific research studies addressing climate change, and multiple lines of scientific evidence now support the conclusions initially made by jones, wigley, and wright in the mid-1980s. Based on the agreement between these multiple datasets, the team of contributing scientists wrote: warming of the climate system is unequivocal, as is now evident from observations of increases in global average air and ocean temperatures, widespread melting of snow and ice, and rising global average sea level. The short phrase "now evident" reflects the accumulation of data over time, including the most recent data up to 2007.

This statement relies on many data sources in addition to the temperature data, including data as diverse as the timing of the first appearance of tree buds in spring, greenhouse gas concentrations in the atmosphere, and measurements of isotopes of oxygen and hydrogen from ice cores. Analyzing and interpreting such a diverse array of datasets requires the combined expertise of the many scientists that contributed to the ipcc report. This type of broad synthesis of data and interpretation is critical to the process of science, highlighting how individual scientists build on the work of others and potentially inspiring collaboration for further research between scientists in different disciplines. Scientific interpretations are neither absolute truth nor personal opinion: they are inferences, suggestions, or hypotheses about what the data mean, based on a foundation of scientific knowledge and individual expertise. When scientists begin to interpret their data, they draw on their personal and collective knowledge, often talking over results with a colleague across the hall or on another continent. They use experience, logic, and parsimony to construct one or more plausible explanations for the data. As within any human endeavor, scientists can make mistakes or even intentionally deceive their peers (see our scientific ethics module), but the vast majority of scientists present interpretations that they feel are most reasonable and supported by the hension scientists disagree on how a set of data is interpreted, this that the data are not valid and the research was a waste of to additional data collection and data available the process of data collection, analysis, and interpretation happens on multiple scales. One of the fundamentally important components of the practice of science is therefore the publication of data in the scientific literature (see our utilizing the scientific literature module). In fact, some research involves re-analysis of data with new techniques, different ways of looking at the data, or combining the results of several studies. For example, in 1997, the collaborative group on hormonal factors in breast cancer published a widely-publicized study in the prestigious medical journal the lancet entitled, "breast cancer and hormone replacement therapy: collaborative reanalysis of data from 51 epidemiological studies of 52,705 women with breast cancer and 108,411 women without breast cancer" (collaborative group on hormonal factors in breast cancer, 1997). By bringing together results from numerous studies and reanalyzing the data together, the researchers concluded that women who were treated with hormone replacement therapy were more like to develop breast cancer. In describing why the reanalysis was used, the authors write: the increase in the relative risk of breast cancer associated with each year of [hrt] use in current and recent users is small, so inevitably some studies would, by chance alone, show significant associations and others would not. In many cases, data collected for other purposes can be used to address new questions. The initial reason for collecting weather data, for example, was to better predict winds and storms to help assure safe travel for trading ships. It is only more recently that interest shifted to long-term changes in the weather, but the same data easily contribute to answering both of those logy for sharing data advances science one of the most exciting advances in science today is the development of public databases of scientific information that can be accessed and used by anyone. For example, climatic and oceanographic data, which are generally very expensive to obtain because they require large-scale operations like drilling ice cores or establishing a network of buoys across the pacific ocean, are shared online through several web sites run by agencies responsible for maintaining and distributing those data, such as the carbon dioxide information analysis center run by the us department of energy (see research under the resources tab). Likewise, the human genome project has a searchable database of the human genome, where researchers can both upload and download their data (see research under the resources tab). The number of these widely available datasets has grown to the point where the national institute of standards and technology actually maintains a database of databases.

Some organizations require their participants to make their data publicly available, such as the incorporated research institutions for seismology (iris): the instrumentation branch of iris provides support for researchers by offering seismic instrumentation, equipment maintenance and training, and logistical field support for experiments. Anyone can apply to use the instruments as long as they provide iris with the data they collect during their seismic experiments. Making data available to other scientists is not a new idea, but having those data available on the internet in a searchable format has revolutionized the way that scientists can interact with the data, allowing for research efforts that would have been impossible before. This collective pooling of data also allows for new kinds of analysis and interpretation on global scales and over long periods of time. In addition, making data easily accessible helps promote interdisciplinary research by opening the doors to exploration by diverse scientists in many analysis is at the heart of any scientific investigation. Using weather as an example, this module takes readers through the steps of data collection, analysis, interpretation, and evaluation. The module explores how scientists collect and record data, find patterns in data, explain those patterns, and share their research with the larger scientific collection is the systematic recording of information; data analysis involves working to uncover patterns and trends in datasets; data interpretation involves explaining those patterns and ists interpret data based on their background knowledge and experience; thus, different scientists can interpret the same data in different publishing their data and the techniques they used to analyze and interpret those data, scientists give the community the opportunity to both review the data and use them in future research.
