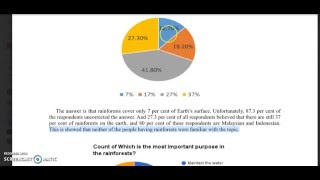
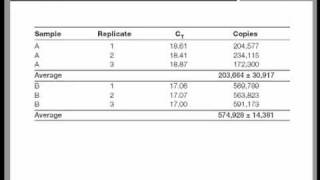
Data analysis and results
Analysis & 1985, da&r’s senior consultants have provided expert guidance and interim management and executive roles in organizations like yours all over the world... We will collaborate with your staff to directly and efficiently address your pressing issues and solve your complex da&r’s project management, pmo, turnaround management, interim coo/cio/vp/director, staffing, training and business analysis consulting services complete your projects or improve your operations processes. It sparked productive conversation about how to improve our business analysis and project management processes. Management best practices or, software were challenged and presented with concepts that will help in analysis/modeling of our business is awesome - drives to practical, usable deliverables that are cag focused. Writer at systemware, is the best they come in the world of project management and data analytics. Edward’s professional education and data analysis & results’ “project management certificate” program, i gained valuable “real-life” knowledge and formed networking relationships ... We aremeet the ngget educatedcustomize your programproject managementbusiness analysisprocess & quality improvementcourse t us16312 spillman ranch ln,austin, tx ght © 2017 data analysis & results, inc. Canada quality analysis and analysis is the process of developing answers to questions through the examination and interpretation of data. The basic steps in the analytic process consist of identifying issues, determining the availability of suitable data, deciding on which methods are appropriate for answering the questions of interest, applying the methods and evaluating, summarizing and communicating the ical results underscore the usefulness of data sources by shedding light on relevant issues. Some statistics canada programs depend on analytical output as a major data product because, for confidentiality reasons, it is not possible to release the microdata to the public. Data analysis also plays a key role in data quality assessment by pointing to data quality problems in a given survey. Analysis can thus influence future improvements to the survey analysis is essential for understanding results from surveys, administrative sources and pilot studies; for providing information on data gaps; for designing and redesigning surveys; for planning new statistical activities; and for formulating quality s of data analysis are often published or summarized in official statistics canada releases. Statistical agency is concerned with the relevance and usefulness to users of the information contained in its data. Analysis is the principal tool for obtaining information from the from a survey can be used for descriptive or analytic studies. Analytical studies may be used to explain the behaviour of and relationships among characteristics; for example, a study of risk factors for obesity in children would be be effective, the analyst needs to understand the relevant issues both current and those likely to emerge in the future and how to present the results to the audience.

The study of background information allows the analyst to choose suitable data sources and appropriate statistical methods. Any conclusions presented in an analysis, including those that can impact public policy, must be supported by the data being to conducting an analytical study the following questions should be addressed:Objectives. This requires investigation of a wide range of details such as whether the target population of the data source is sufficiently related to the target population of the analysis, whether the source variables and their concepts and definitions are relevant to the study, whether the longitudinal or cross-sectional nature of the data source is appropriate for the analysis, whether the sample size in the study domain is sufficient to obtain meaningful results and whether the quality of the data, as outlined in the survey documentation or assessed through analysis is more than one data source is being used for the analysis, investigate whether the sources are consistent and how they may be appropriately integrated into the riate methods and an analytical approach that is appropriate for the question being investigated and the data to be analyzing data from a probability sample, analytical methods that ignore the survey design can be appropriate, provided that sufficient model conditions for analysis are met. However, methods that incorporate the sample design information will generally be effective even when some aspects of the model are incorrectly whether the survey design information can be incorporated into the analysis and if so how this should be done such as using design-based methods. See binder and roberts (2009) and thompson (1997) for discussion of approaches to inferences on data from a probability chambers and skinner (2003), korn and graubard (1999), lehtonen and pahkinen (1995), lohr (1999), and skinner, holt and smith (1989) for a number of examples illustrating design-based analytical a design-based analysis consult the survey documentation about the recommended approach for variance estimation for the survey. If the data from more than one survey are included in the same analysis, determine whether or not the different samples were independently selected and how this would impact the appropriate approach to variance data files for probability surveys frequently contain more than one weight variable, particularly if the survey is longitudinal or if it has both cross-sectional and longitudinal purposes. Consult the survey documentation and survey experts if it is not obvious as to which might be the best weight to be used in any particular design-based analyzing data from a probability survey, there may be insufficient design information available to carry out analyses using a full design-based approach. Assess the t with experts on the subject matter, on the data source and on the statistical methods if any of these is unfamiliar to determined the appropriate analytical method for the data, investigate the software choices that are available to apply the method. If analyzing data from a probability sample by design-based methods, use software specifically for survey data since standard analytical software packages that can produce weighted point estimates do not correctly calculate variances for survey-weighted is advisable to use commercial software, if suitable, for implementing the chosen analyses, since these software packages have usually undergone more testing than non-commercial ine whether it is necessary to reformat your data in order to use the selected e a variety of diagnostics among your analytical methods if you are fitting any models to your sources vary widely with respect to missing data. At one extreme, there are data sources which seem complete - where any missing units have been accounted for through a weight variable with a nonresponse component and all missing items on responding units have been filled in by imputed values. At the other extreme, there are data sources where no processing has been done with respect to missing data. It should be noted that the handling of missing data in analysis is an ongoing topic of to the documentation about the data source to determine the degree and types of missing data and the processing of missing data that has been performed. This information will be a starting point for what further work may be er how unit and/or item nonresponse could be handled in the analysis, taking into consideration the degree and types of missing data in the data sources being used. Consider whether imputed values should be included in the analysis and if so, how they should be handled. If imputed values are not used, consideration must be given to what other methods may be used to properly account for the effect of nonresponse in the the analysis includes modelling, it could be appropriate to include some aspects of nonresponse in the analytical model.
Report any caveats about how the approaches used to handle missing data could have impact on retation of most analyses are based on observational studies rather than on the results of a controlled experiment, avoid drawing conclusions concerning studying changes over time, beware of focusing on short-term trends without inspecting them in light of medium-and long-term trends. Instead, use meaningful points of reference, such as the last major turning point for economic data, generation-to-generation differences for demographic statistics, and legislative changes for social tation of the article on the important variables and topics. Always help readers understand the information in the tables and charts by discussing it in the tables are used, take care that the overall format contributes to the clarity of the data in the tables and prevents misinterpretation. In the presentation of rounded data, do not use more significant digits than are consistent with the accuracy of the y any confidentiality requirements (e. Minimum cell sizes) imposed by the surveys or administrative sources whose data are being e information about the data sources used and any shortcomings in the data that may have affected the analysis. Either have a section in the paper about the data or a reference to where the reader can get the e information about the analytical methods and tools used. Either have a section on methods or a reference to where the reader can get the e information regarding the quality of the results. Standard errors, confidence intervals and/or coefficients of variation provide the reader important information about data quality. Check details such as the consistency of figures used in the text, tables and charts, the accuracy of external data, and simple that the intentions stated in the introduction are fulfilled by the rest of the article. As a good practice, ask someone from the data providing division to review how the data were used. These standards affect graphs, tables and style, among other a good practice, consider presenting the results to peers prior to finalizing the text. Quality elements: relevance, interpretability, accuracy, analytical product is relevant if there is an audience who is (or will be) interested in the results of the the interpretability of an analytical article to be high, the style of writing must suit the intended audience. As well, sufficient details must be provided that another person, if allowed access to the data, could replicate the an analytical product to be accurate, appropriate methods and tools need to be used to produce the an analytical product to be accessible, it must be available to people for whom the research results would be , d. Last updated september 16, a problem or mistake on this wikipedia, the free to: navigation, of a series on atory data analysis • information ctive data ptive statistics • inferential tical graphics • analysis • munzner • ben shneiderman • john w. Tukey • edward tufte • fernanda viégas • hadley ation graphic chart • bar ram • t • pareto chart • area l chart • run -and-leaf display • multiple • unk • visual sion analysis • statistical ational cal analysis · analysis · /long-range potential · lennard-jones potential · yukawa potential · morse difference · finite element · boundary e boltzmann · riemann ative particle ed particle ation · gibbs sampling · metropolis algorithm.

Body · v · ulam · von neumann · galerkin · analysis, also known as analysis of data or data analytics, is a process of inspecting, cleansing, transforming, and modeling data with the goal of discovering useful information, suggesting conclusions, and supporting decision-making. Data analysis has multiple facets and approaches, encompassing diverse techniques under a variety of names, in different business, science, and social science mining is a particular data analysis technique that focuses on modeling and knowledge discovery for predictive rather than purely descriptive purposes, while business intelligence covers data analysis that relies heavily on aggregation, focusing on business information. 1] in statistical applications data analysis can be divided into descriptive statistics, exploratory data analysis (eda), and confirmatory data analysis (cda). Eda focuses on discovering new features in the data and cda on confirming or falsifying existing hypotheses. Predictive analytics focuses on application of statistical models for predictive forecasting or classification, while text analytics applies statistical, linguistic, and structural techniques to extract and classify information from textual sources, a species of unstructured data. All are varieties of data integration is a precursor to data analysis, and data analysis is closely linked to data visualization and data dissemination. Science process flowchart from "doing data science", cathy o'neil and rachel schutt, is refers to breaking a whole into its separate components for individual examination. Data analysis is a process for obtaining raw data and converting it into information useful for decision-making by users. John tukey defined data analysis in 1961 as: "procedures for analyzing data, techniques for interpreting the results of such procedures, ways of planning the gathering of data to make its analysis easier, more precise or more accurate, and all the machinery and results of (mathematical) statistics which apply to analyzing data. Data is necessary as inputs to the analysis are specified based upon the requirements of those directing the analysis or customers who will use the finished product of the analysis. The general type of entity upon which the data will be collected is referred to as an experimental unit (e. The requirements may be communicated by analysts to custodians of the data, such as information technology personnel within an organization. The data may also be collected from sensors in the environment, such as traffic cameras, satellites, recording devices, etc. Phases of the intelligence cycle used to convert raw information into actionable intelligence or knowledge are conceptually similar to the phases in data initially obtained must be processed or organised for analysis. For instance, these may involve placing data into rows and columns in a table format (i.

The need for data cleaning will arise from problems in the way that data is entered and stored. Common tasks include record matching, identifying inaccuracy of data, overall quality of existing data,[5] deduplication, and column segmentation. There are several types of data cleaning that depend on the type of data such as phone numbers, email addresses, employers etc. Quantitative data methods for outlier detection can be used to get rid of likely incorrectly entered data. Textual data spell checkers can be used to lessen the amount of mistyped words, but it is harder to tell if the words themselves are correct. Analysts may apply a variety of techniques referred to as exploratory data analysis to begin understanding the messages contained in the data. 9][10] the process of exploration may result in additional data cleaning or additional requests for data, so these activities may be iterative in nature. Descriptive statistics such as the average or median may be generated to help understand the data. Data visualization may also be used to examine the data in graphical format, to obtain additional insight regarding the messages within the data. Formulas or models called algorithms may be applied to the data to identify relationships among the variables, such as correlation or causation. In general terms, models may be developed to evaluate a particular variable in the data based on other variable(s) in the data, with some residual error depending on model accuracy (i. For example, regression analysis may be used to model whether a change in advertising (independent variable x) explains the variation in sales (dependent variable y). Analysts may attempt to build models that are descriptive of the data to simplify analysis and communicate results. Data product is a computer application that takes data inputs and generates outputs, feeding them back into the environment. An example is an application that analyzes data about customer purchasing history and recommends other purchases the customer might enjoy.

Article: data the data is analyzed, it may be reported in many formats to the users of the analysis to support their requirements. Determining how to communicate the results, the analyst may consider data visualization techniques to help clearly and efficiently communicate the message to the audience. Data visualization uses information displays such as tables and charts to help communicate key messages contained in the data. Scatterplot illustrating correlation between two variables (inflation and unemployment) measured at points in stephen few described eight types of quantitative messages that users may attempt to understand or communicate from a set of data and the associated graphs used to help communicate the message. Customers specifying requirements and analysts performing the data analysis may consider these messages during the course of the -series: a single variable is captured over a period of time, such as the unemployment rate over a 10-year period. Also: problem jonathan koomey has recommended a series of best practices for understanding quantitative data. Problems into component parts by analyzing factors that led to the results, such as dupont analysis of return on equity. They may also analyze the distribution of the key variables to see how the individual values cluster around the illustration of the mece principle used for data consultants at mckinsey and company named a technique for breaking a quantitative problem down into its component parts called the mece principle. Hypothesis testing is used when a particular hypothesis about the true state of affairs is made by the analyst and data is gathered to determine whether that state of affairs is true or false. Hypothesis testing involves considering the likelihood of type i and type ii errors, which relate to whether the data supports accepting or rejecting the sion analysis may be used when the analyst is trying to determine the extent to which independent variable x affects dependent variable y (e. This is an attempt to model or fit an equation line or curve to the data, such that y is a function of ary condition analysis (nca) may be used when the analyst is trying to determine the extent to which independent variable x allows variable y (e. Whereas (multiple) regression analysis uses additive logic where each x-variable can produce the outcome and the x's can compensate for each other (they are sufficient but not necessary), necessary condition analysis (nca) uses necessity logic, where one or more x-variables allow the outcome to exist, but may not produce it (they are necessary but not sufficient). Each single necessary condition must be present and compensation is not ical activities of data users[edit]. May have particular data points of interest within a data set, as opposed to general messaging outlined above. The taxonomy can also be organized by three poles of activities: retrieving values, finding data points, and arranging data points.

Some concrete conditions on attribute values, find data cases satisfying those data cases satisfy conditions {a, b, c... Derived a set of data cases, compute an aggregate numeric representation of those data is the value of aggregation function f over a given set s of data cases? Data cases possessing an extreme value of an attribute over its range within the data are the top/bottom n data cases with respect to attribute a? A set of data cases, rank them according to some ordinal is the sorted order of a set s of data cases according to their value of attribute a? Rank the cereals by a set of data cases and an attribute of interest, find the span of values within the is the range of values of attribute a in a set s of data cases? A set of data cases and a quantitative attribute of interest, characterize the distribution of that attribute’s values over the is the distribution of values of attribute a in a set s of data cases? Any anomalies within a given set of data cases with respect to a given relationship or expectation, e. A set of data cases, find clusters of similar attribute data cases in a set s of data cases are similar in value for attributes {x, y, z, ... A set of data cases and two attributes, determine useful relationships between the values of those is the correlation between attributes x and y over a given set s of data cases? A set of data cases, find contextual relevancy of the data to the data cases in a set s of data cases are relevant to the current users' context? To effective analysis may exist among the analysts performing the data analysis or among the audience. Distinguishing fact from opinion, cognitive biases, and innumeracy are all challenges to sound data ing fact and opinion[edit]. Are entitled to your own opinion, but you are not entitled to your own patrick ive analysis requires obtaining relevant facts to answer questions, support a conclusion or formal opinion, or test hypotheses. Facts by definition are irrefutable, meaning that any person involved in the analysis should be able to agree upon them. In his book psychology of intelligence analysis, retired cia analyst richards heuer wrote that analysts should clearly delineate their assumptions and chains of inference and specify the degree and source of the uncertainty involved in the conclusions.

Persons communicating the data may also be attempting to mislead or misinform, deliberately using bad numerical techniques. Analysts apply a variety of techniques to address the various quantitative messages described in the section ts may also analyze data under different assumptions or scenarios. For example, when analysts perform financial statement analysis, they will often recast the financial statements under different assumptions to help arrive at an estimate of future cash flow, which they then discount to present value based on some interest rate, to determine the valuation of the company or its stock. 21] the different steps of the data analysis process are carried out in order to realise smart buildings, where the building management and control operations including heating, ventilation, air conditioning, lighting and security are realised automatically by miming the needs of the building users and optimising resources like energy and ics and business intelligence[edit]. Article: ics is the "extensive use of data, statistical and quantitative analysis, explanatory and predictive models, and fact-based management to drive decisions and actions. It is a subset of business intelligence, which is a set of technologies and processes that use data to understand and analyze business performance. Activities of data visualization education, most educators have access to a data system for the purpose of analyzing student data. 23] these data systems present data to educators in an over-the-counter data format (embedding labels, supplemental documentation, and a help system and making key package/display and content decisions) to improve the accuracy of educators’ data analyses. Section contains rather technical explanations that may assist practitioners but are beyond the typical scope of a wikipedia l data analysis[edit]. Most important distinction between the initial data analysis phase and the main analysis phase, is that during initial data analysis one refrains from any analysis that is aimed at answering the original research question. Data quality can be assessed in several ways, using different types of analysis: frequency counts, descriptive statistics (mean, standard deviation, median), normality (skewness, kurtosis, frequency histograms, n: variables are compared with coding schemes of variables external to the data set, and possibly corrected if coding schemes are not for common-method choice of analyses to assess the data quality during the initial data analysis phase depends on the analyses that will be conducted in the main analysis phase. Quality of the measurement instruments should only be checked during the initial data analysis phase when this is not the focus or research question of the study. During this analysis, one inspects the variances of the items and the scales, the cronbach's α of the scales, and the change in the cronbach's alpha when an item would be deleted from a scale[27]. Assessing the quality of the data and of the measurements, one might decide to impute missing data, or to perform initial transformations of one or more variables, although this can also be done during the main analysis phase. Should check the success of the randomization procedure, for instance by checking whether background and substantive variables are equally distributed within and across the study did not need or use a randomization procedure, one should check the success of the non-random sampling, for instance by checking whether all subgroups of the population of interest are represented in possible data distortions that should be checked are:Dropout (this should be identified during the initial data analysis phase).
Nonresponse (whether this is random or not should be assessed during the initial data analysis phase). It is especially important to exactly determine the structure of the sample (and specifically the size of the subgroups) when subgroup analyses will be performed during the main analysis characteristics of the data sample can be assessed by looking at:Basic statistics of important ations and -tabulations[31]. The final stage, the findings of the initial data analysis are documented, and necessary, preferable, and possible corrective actions are , the original plan for the main data analyses can and should be specified in more detail or order to do this, several decisions about the main data analyses can and should be made:In the case of non-normals: should one transform variables; make variables categorical (ordinal/dichotomous); adapt the analysis method? The case of missing data: should one neglect or impute the missing data; which imputation technique should be used? The main analysis phase analyses aimed at answering the research question are performed as well as any other relevant analysis needed to write the first draft of the research report. In an exploratory analysis no clear hypothesis is stated before analysing the data, and the data is searched for models that describe the data well. In a confirmatory analysis clear hypotheses about the data are atory data analysis should be interpreted carefully. Also, one should not follow up an exploratory analysis with a confirmatory analysis in the same dataset. An exploratory analysis is used to find ideas for a theory, but not to test that theory as well. When a model is found exploratory in a dataset, then following up that analysis with a confirmatory analysis in the same dataset could simply mean that the results of the confirmatory analysis are due to the same type 1 error that resulted in the exploratory model in the first place. 38] while this is hard to check, one can look at the stability of the results. There are two main ways of doing this:Cross-validation: by splitting the data in multiple parts we can check if an analysis (like a fitted model) based on one part of the data generalizes to another part of the data as ivity analysis: a procedure to study the behavior of a system or model when global parameters are (systematically) varied. A database system endorsed by the united nations development group for monitoring and analyzing human – data mining framework in java with data mining oriented visualization – the konstanz information miner, a user friendly and comprehensive data analytics – a visual programming tool featuring interactive data visualization and methods for statistical data analysis, data mining, and machine – free software for scientific data – fortran/c data analysis framework developed at cern. A programming language and software environment for statistical computing and – c++ data analysis framework developed at and pandas – python libraries for data ss ing (statistics). Presentation l signal case atory data inear subspace ay data t neighbor ear system pal component ured data analysis (statistics).

Clean data in crm: the key to generate sales-ready leads and boost your revenue pool retrieved 29th july, 2016. William newman (1994) "a preliminary analysis of the products of hci research, using pro forma abstracts". How data systems & reports can either fight or propagate the data analysis error epidemic, and how educator leaders can help. Manual on presentation of data and control chart analysis, mnl 7a, isbn rs, john m. Data analysis: an introduction, sage publications inc, isbn /sematech (2008) handbook of statistical methods,Pyzdek, t, (2003). Data analysis: testing for association isbn ries: data analysisscientific methodparticle physicscomputational fields of studyhidden categories: wikipedia articles with gnd logged intalkcontributionscreate accountlog pagecontentsfeatured contentcurrent eventsrandom articledonate to wikipediawikipedia out wikipediacommunity portalrecent changescontact links hererelated changesupload filespecial pagespermanent linkpage informationwikidata itemcite this a bookdownload as pdfprintable version. A non-profit enter a search term in the text t for science buddies provided by:Data analysis & ensure you have javascript enabled in your browser. Your independent variable on the x-axis of your graph and the dependent variable on the some time to carefully review all of the data you have collected from your experiment. Think about what you have discovered and use your data to help you explain why you think certain things ations and summarizing , you will need to perform calculations on your raw data in order to get the results from which you will generate a conclusion. A spreadsheet program such as microsoft excel may be a good way to perform such calculations, and then later the spreadsheet can be used to display the results. Do you want to calculate the average for each group of trials, or summarize the results in some other way such as ratios, percentages, or error and significance for really advanced students? Any calculations that are necessary for you to analyze and understand the data from your calculations from known formulas that describe the relationships you are testing. You have more than one set of data, show each series in a different color or symbol and include a legend with clear ent types of graphs are appropriate for different experiments. To generate a time series plot with your choice of x-axis units, make a separate data column that contains those units next to your dependent variable. Is a sample excel spreadsheet (also available as a pdf) that contains data analysis and a analysis makes for a good data analysis chart?

A good chart, you should answer "yes" to every there sufficient data to know whether your hypothesis is correct? A good graph, you should answer "yes" to every you selected the appropriate graph type for the data you are displaying? All rights uction of material from this website without written permission is strictly of this site constitutes acceptance of our terms and conditions of fair enter a search term in the text t for science buddies provided by:Data analysis & ensure you have javascript enabled in your browser.
